
A Comprehensive Study of Text Classification Algorithms.!
A Comprehensive Study of Text Classification Algorithms
Abstract
Huge amount of data in today’s world are stored in the form of electronic documents. Text mining is the process of extracting the information out of those textual documents. Text classification is the process of classifying text documents into fixed number of predefined classes. The application of text classification includes spam filtering, email routing, sentiment analysis, language identification etc. This paper discusses a detailed survey on the text classification process and various algorithms used in this field.
INTRODUCTION
Text classification is the process of classifying text documents into a predefined set of classes. It is a supervised learning approach in which a training set of documents {D1, D2….Dn} labelled with classes from {1…..m} are used to build
a classification model and predicts the class label of a new incoming document based on the training model. Text classification types include single label and multi-label classification. When a document is assigned with only one class it is called single labelled and when more than one class is assigned for a document it becomes multi-label classification. Binary classification which predicts if a document belongs to a particular class or not is the best example of a single label classification. Text categorization has various stages such as pre-processing, indexing and dimensionality reduction, classification and performance evaluation.
In pre-processing, the text documents are split into small tokens which may be words or phrases. These tokens are subjected to stop word removal process which removes the most frequent insignificant words like ‘the’, ‘a’ etc. Stemming is also applied to those token streams for converting the words to its root form.
The contents of text documents has to be represented in some form before being fed into a classifier, this is called Indexing. The features or terms are used to represent a document. The terms may be words or phrases. A commonly used scheme is the Bag of the words model which represents the document as set of words or a word vector. The weight assigned to the word will decide the relevance of the word in the document. Binary Indexing assigns a weight 1 if the word is present in the document and 0 if it is not. TF-IDF is another
weighting method which assigns a weight taking into account the Term Frequency and Inverse Document Frequency. It gives higher weight for a word in the document if the Term Frequency i.e. number of times the word appearing in the document is high and less weight if the Document Frequency i.e. the no of training documents in which the word appearing is high. TF-IDF score doesn’t take the semantics of the document into consideration which is seen as a disadvantage of this method. There are also other Indexing methods including probabilistic methods and the selection of Indexing methods for a classification model are very much dependent on the availability of training samples.
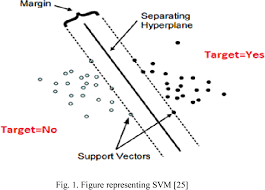
Dimensionality Reduction reduces the feature vector space of the documents by selecting or extracting a subset of terms out of the original one. A classifier yields a better result if the Dimensionality Reduction technique were applied before classification. Document Frequency which selects the highest frequent words across documents is an effective feature selection method. There are also other methods based on Information Theory like Information Gain, Mutual Information, DIA Association Factor, Chi-Square, NGL Coefficient, Odds Ratio etc. These methods are observed to be more efficient and outperforms Document Frequency by fair margin. Another way of Dimensionality Reduction is by feature extraction. Here the extracted features may not be the subset terms but a compact representation of the features. Some of the methods used in this scenario are Term Clustering and Latent Semantic Indexing (LSI). Term Clustering tries to cluster the terms and represent the feature vector space with a cluster member. LSI uses single value decomposition to transform a higher dimensional vector to a lower dimensional one. The feature extraction handles the problems of polysemy and synonymy well, discriminating this from other methods.
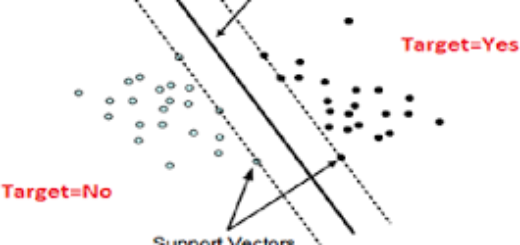
Now comes the classification which is applied onto the pre-processed text data. There are several classifiers such as Decision Tree classifiers, Rule Based classifiers, Probabilistic and Naïve Bayes classifiers, Regression Based classifiers, Proximity Based classifiers, Neural Network Classifiers etc. All the classifiers have its own good and bad making them suitable for specific models. We will give an elaborate discussion on classifiers in the coming sections.
The final stage provides a performance analysis of these classifiers. The different metrics used here includes Precision, Recall, Error, Accuracy etc.




























Thiѕ is my first time ᴠisit at here and i am actually happy to read all at one place.
Xenical 120 Mg cialis online Tamoxifen Order Online Propecia Nioxin Follicle Booster
I have a small lump under my left armpit, could it be cancerous? | Yahoo Answers
painless lump in armpit
Apr 16, 2019 Dental Hygienist, in Salt Lake City Dental Hygienist needed for Tuesdays Posting Date:Apr 16, 2019; Closing Date:May 31, 2019; Salary
Newfoundland dog names
Dental hygienists are recognized as licensed dental health professionals in every US jurisdiction. This means that to practice as a dental hygienist, all.
Dental hygienist salary texas